

You’ve probably heard of Machine Learning (ML), and may be familiar with the idea that ML is a way for computers to get better (“learn”) at doing things like recognizing the image of a cat or the words that you’ve said when you call into a contact center.
And you may have also heard of Deep Learning. Like most people you probably just assume that Deep Learning is a better, more powerful version of ML, and you’d be right to assume so. But as more organizations adopt advanced machine learning, it’s worth understanding Deep Learning a little bit more to understand why it’s so powerful.
The Basics of Deep Learning
Though the math can get complicated, the concepts behind Deep Learning are pretty straightforward. The first concept to understand is that Deep Learning uses the idea of an Artificial Neural Network (ANN). A Neural Network, modeled on the human brain, is a connected set (Network) of things that can each hold a value (Neurons). An Artificial Neural Network is just a Neural Network based inside a computer, instead of inside our brains.
You can think of an ANN as a set of layers. Each layer has a set of neurons (circles in the diagram below) that can hold a value, generally between 0 and 1. The first layer, on the left, has inputs that humans define—for instance, how light or dark (on a scale of 0 to 1) a pixel is in a black and white photo of an animal. The last layer, on the far right, has values that represent the confidence level (also between 0 and 1) that the input matches an output—for example, identifying whether that photo is a cat, a dog or some other animal (each circle on the right represents one animal). The layers in between—and there might be just a couple or hundreds—are sometimes called “hidden layers.” The meaning in the hidden layers isn’t defined by humans, but are the calculation stages that the computer goes through to get from the left (input) layer to the right (output) layer.
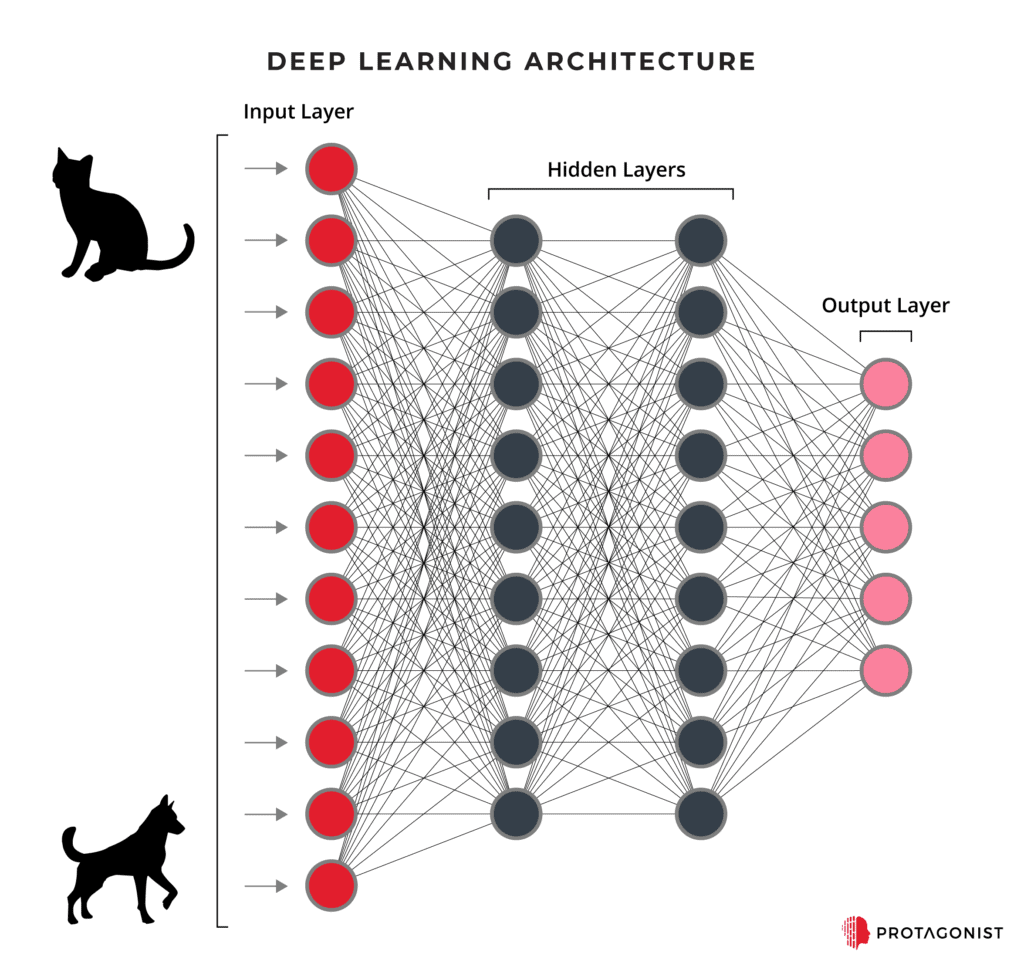
So, humans define the inputs (pixel values in the animal example) and the output choices (animal types in the example). And humans define some of what goes on in the hidden layers—like how many layers there are, and what kind of math the machine should use to “learn.” But how does the machine learn?
Basically, the machine learns by repeating three steps. First, it sets some initial variables that use the neuron values in one layer to calculate the values in the next layer, moving left to right. Second, it looks at the results of those calculations in the output layer to see how accurate it is. And third, it adjusts the variables over and over again to get more and more accurate.
For instance, after setting the initial variables and calculating from left to right, the machine may say a particular image is a dog, because it calculated an output confidence level of 0.75 for a dog and only 0.25 for a cat. Then it checks that conclusion against what humans have told it about that image (in a set of training data). Let’s say that image was actually a cat in the training set. In that case, the machine is 0.75 away from the correct conclusion (1.00 – 0.25 certainty level for a cat). The machine adds up the errors for all the images it tested, to get a total measure of error, called the “Cost” of setting the factors the way it did. The first time through, the Cost is going to be very high (the machine is going to get a lot wrong). So, it then goes back through and adjusts all the factors it originally set, using mathematical techniques to try to get to more accurate factors as quickly as possible, and calculates the Cost again. This time it’s closer, so it keeps repeating this process until it reaches an acceptable level of accuracy.
And that’s it. The machine has “learned” how to identify pictures accurately, just by performing a lot of calculations and adjustments on large training sets. And the fact that we now have those two things—enough computing power to perform calculations and adjustments, and enough examples in training sets—are the reasons why Deep Learning is now possible.
What Does This Mean for You?
Of course, most of us don’t spend our time writing sophisticated Deep Learning algorithms, so why should we care about all this? The short answer is you should care because Deep Learning has the power to make your life better.
This is especially true for our clients, who want to understand on a deeper level the attitudes, beliefs and opinions that shape human action. That means they need to go beyond simple metrics like mentions and rough sentiment to understand the nuances of human expression, across thousands to billions of data points. Thanks to Deep Learning, we now have the ability to better understand what customers think about your company, detect attitudes around the world toward global powers, and comprehend nuanced opinions about the most important social issues we face. Whether you’re a marketer, a communicator, a strategist or a change agent, the enhanced understanding of expressions at scale—enabled by Deep Learning—is a change to look forward to.